Les moteurs de recherche
Comment trouver les pages web ?
Le web est constitué de plusieurs milliards de documents. Les internautes utilisent donc les moteurs de recherche pour trouver une ressource parmi cette jungle.
Les moteurs de recherche (Google, Yahoo, Bing, ...) utilisent des robots : les bots ou crawlers ou spiders.
Ces robots sont des processus informatiques qui se contentent de lire une page web, d'y extraire les liens et d'aller visiter ultérieurement les liens trouvés. En suivant les pages, de liens en liens, ces robots sont capables de visiter pratiquement tout le web.

Il y a cependant des limitations :
Il n'est normalement pas possible pour ces robots de trouver une page orpheline (page qui ne reçoit aucun lien)
Le web étant si grand, les robots ne peuvent tout indexer et mettre à jour rapidement. Selon le moteur de recherche et la méthodologie qui lui est associé, une page peut être revisitée quelques heures après sa publication ou plusieurs mois après.
Comment sauvegarder les pages ?
Une fois qu'un robot à visité une page, il va l'enregistrer dans des énormes data-center. Ces derniers enregistrent ainsi des milliards et des milliards de pages web.
L'étape suivante consiste pour le moteur de recherche à extraire les informations et à les indexer.
Sachant que les robots ne sont que ces processus d'information, ils sont en général capables de lire uniquement le contenu textuel (pas les bandes son ni les images).
En langage informatique, un index est similaire au principe des index utilisé dans les livres. L'index recense les mots et l'endroit où ils sont présents. Par exemple, l'index peut indiquer que le mot "mondialisation" est utilisé sur les pages 1, 14 et 32. Cela permettra de gagner du temps lorsqu'un visiteur effectuera une requête.
Lorsqu'on effectue une recherche, il y a souvent des millions de pages qui possèdent le mot recherché. Les moteurs doivent donc classer les résultats par pertinence.
Il y a deux grands critères qui influent le classement des résultats :
la pertinence : présence du mot dans le titre ? dans l'URL ? dans le contenu ?
la popularité : nombre de liens de la page ? Ces liens proviennent-ils de pages populaires, traitant de la même thématique, dans la même langue ? Sont-ils des sites de confiance ? ...
D'autres critères peuvent être pris en compte. Par exemple, le moteur de recherche Google base ses résultats selon la localité du visiteur et selon l'historique des précédentes recherches effectuées.
Rapidité de la recherche ?
Le moteur de recherche ne cherche pas sur le web, mais cherche plutôt sur ce qui est connu des moteurs de recherche et indexé. Il utilise le principe des index, comme dans l'index d'un livre qui indique les pages qui contiennent le(s) mot(s) recherchés.
Certains moteurs de recherche n'utilisent pas un super ordinateur, mais un réseau de très nombreux ordinateurs à capacités normales. Les performances sont beaucoup plus notables.
De plus, sachant que certaines requêtes sont très populaires, les moteurs préparent à l'avance les résultats donnant ainsi directement les résultats sans avoir à chercher dans l'index.
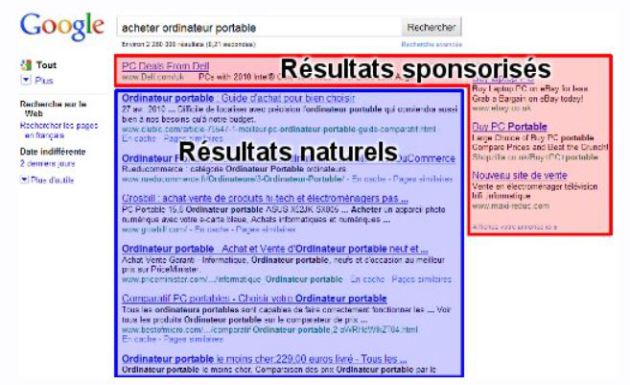
Pour gagner de l'argent, le moteur de recherche affiche des résultats sponsorisés en lien avec la recherche. Des sites web payent donc les moteurs pour que leur site soit en tête de certains résultats, mais uniquement dans la partie réservée aux résultats sponsorisés.